A core value of ours at Designer Cloud is to start with the user, and our product team has made a huge effort to interview our user community and take feedback on areas for improvement. I’d like to highlight one major improvement that exemplifies this focus at Designer Cloud and is the culmination of a lot of excellent feedback–the Join redesign for a faster and easier data blending experience.
We have reimagined the whole data blending experience to keep you inside the core transformer grid and give ultimate visibility into the join. Seamlessly select datasets or recipes to join with, edit or affirm suggested join keys, select columns and review the join in the Transformer grid–all while helpful visual guides and metadata provide important context for your join.
Data Selection for data blending
Initiating a Join will give you a dataset selection pop up with a contextually organized list of recipes and datasets to choose from. A preview of the data and recipe provides helpful validation to ensure you are joining with the correct data.
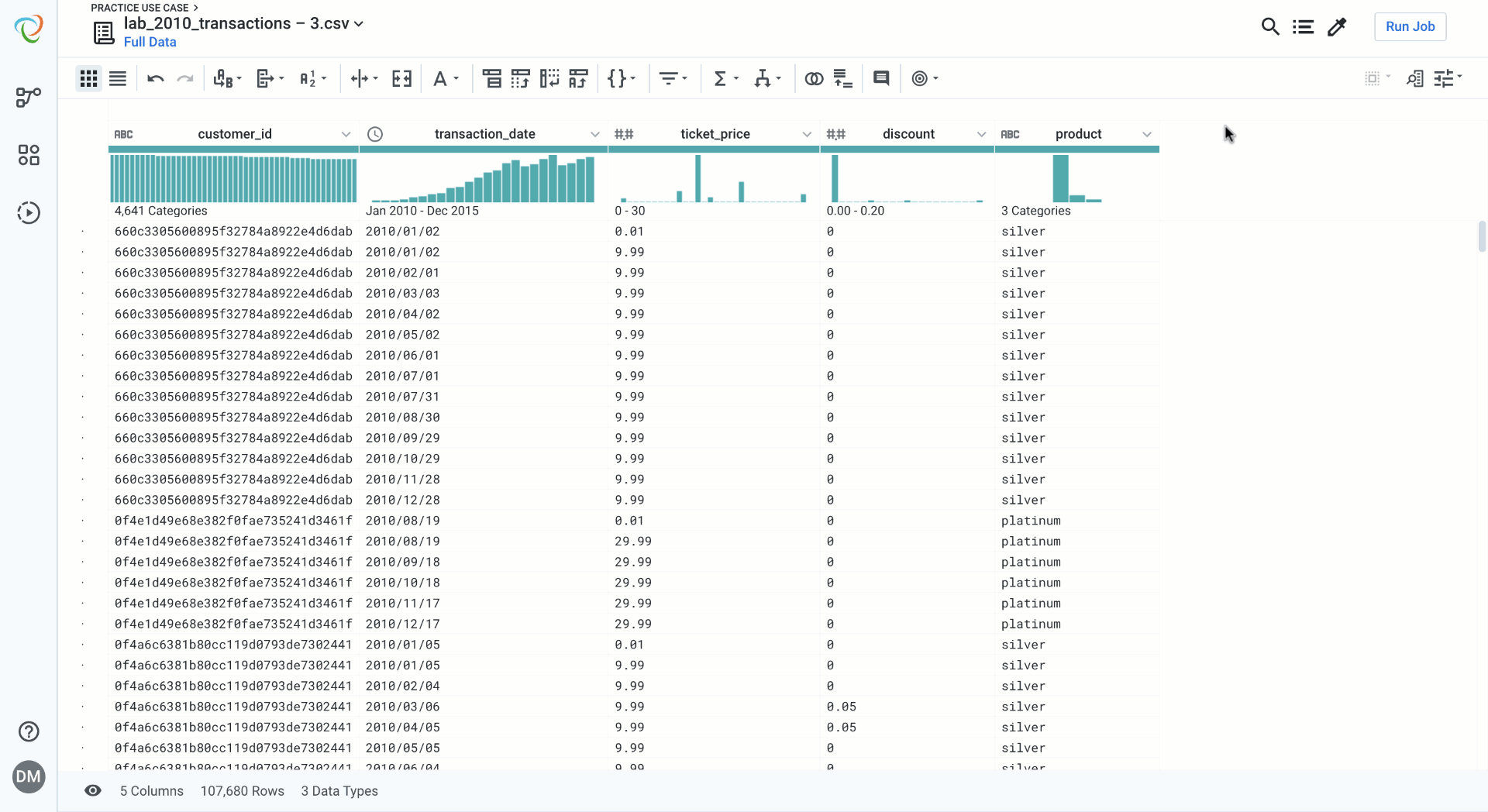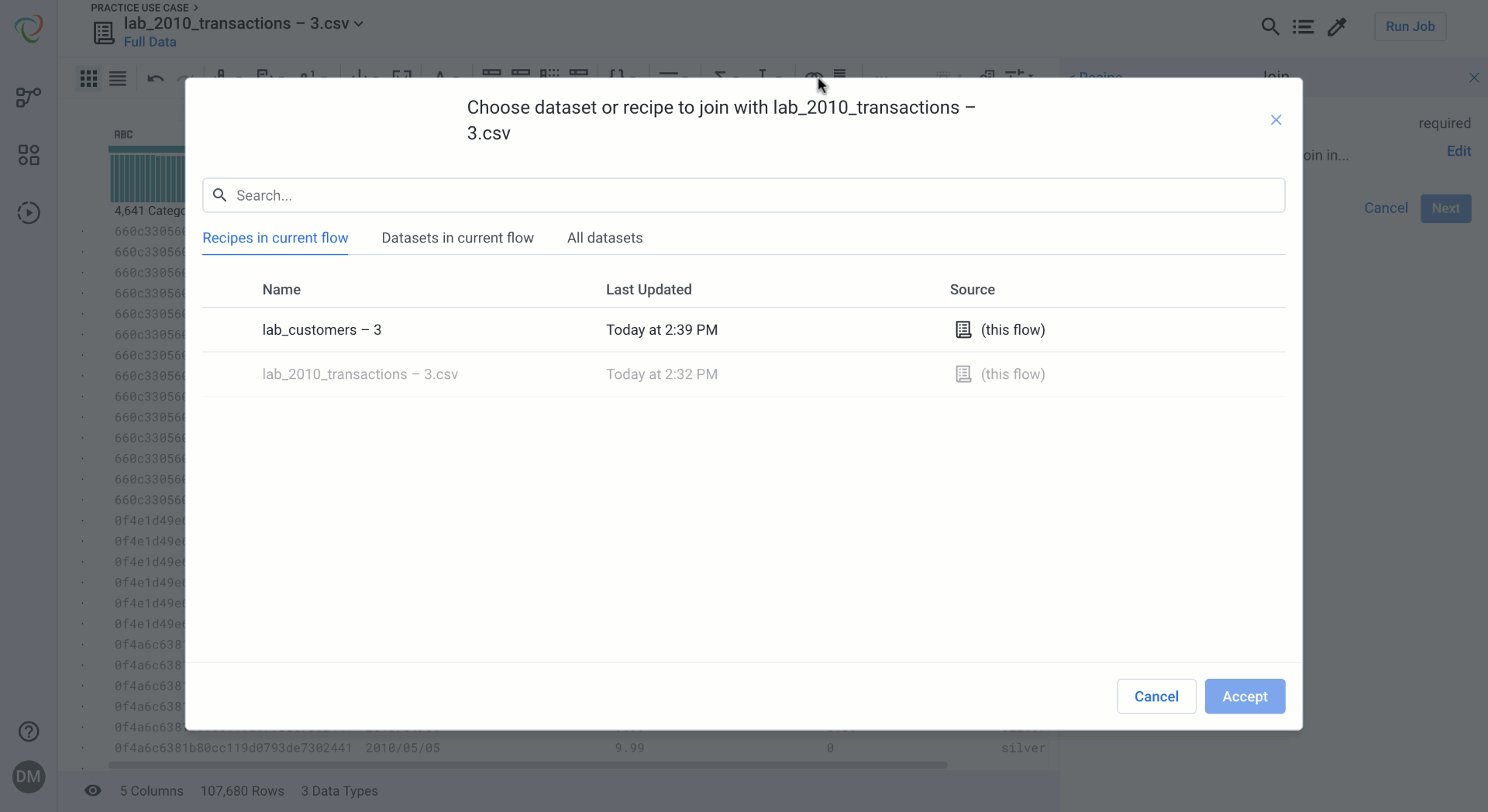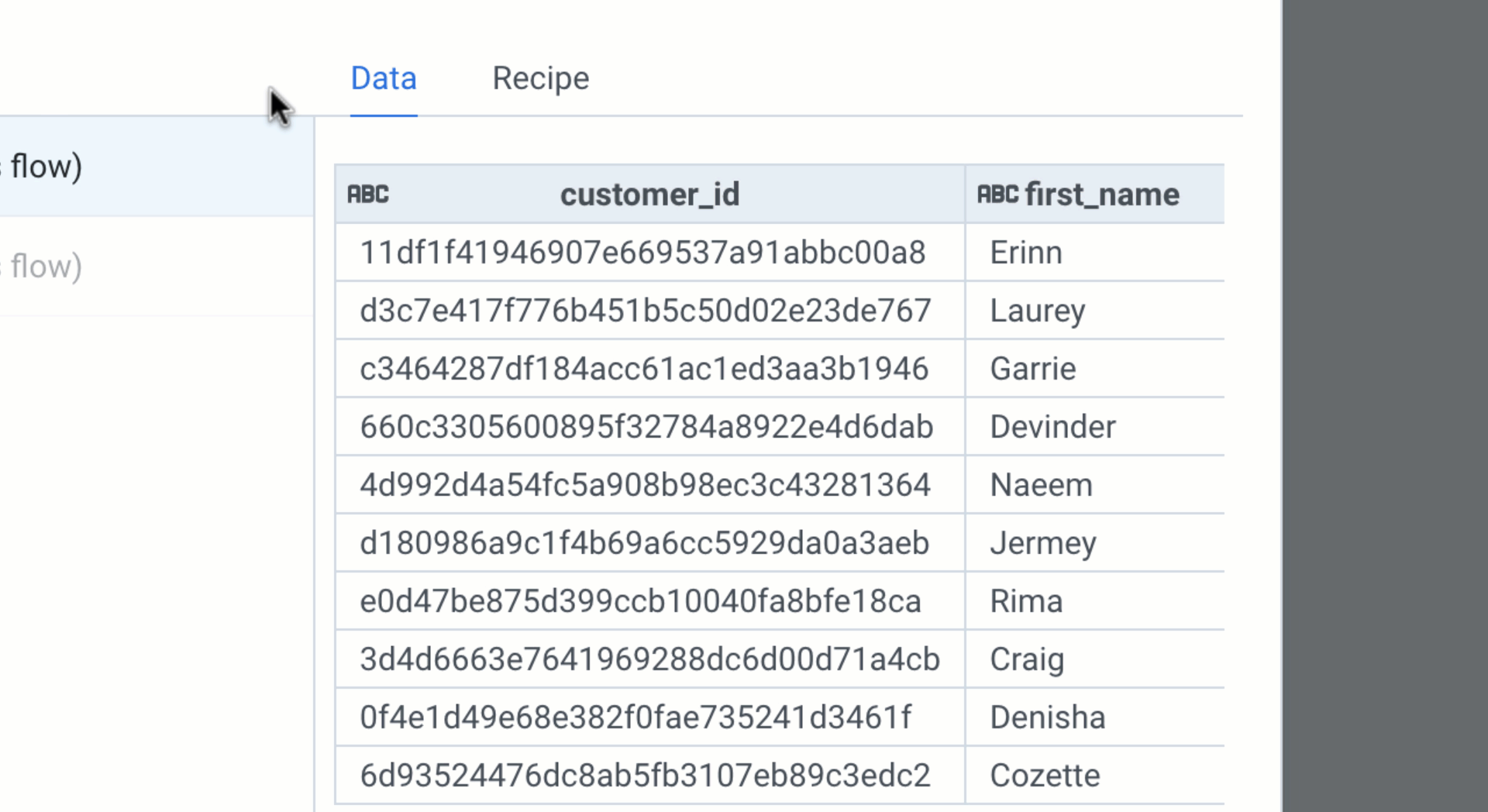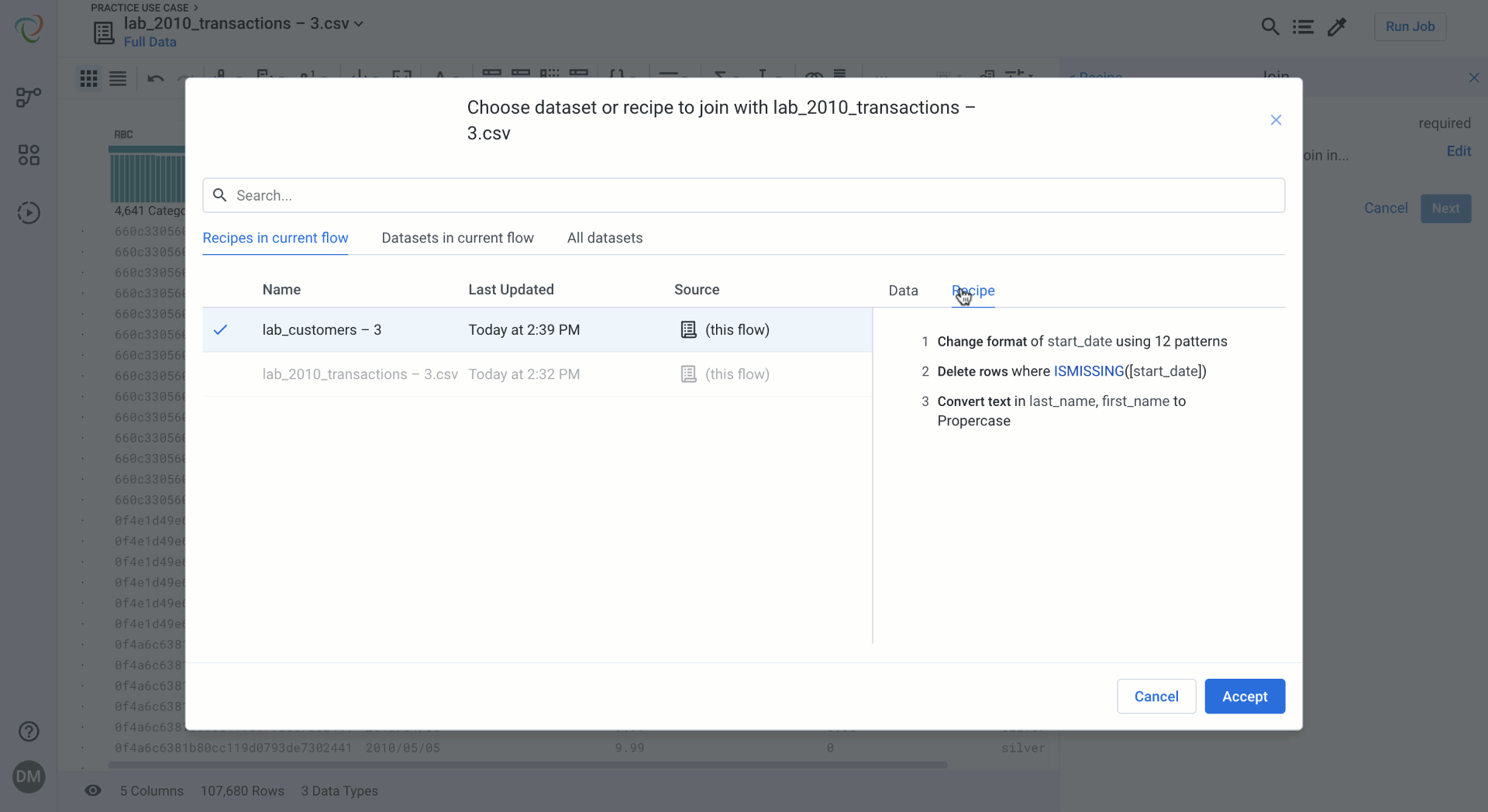
Join setup for Data Blending
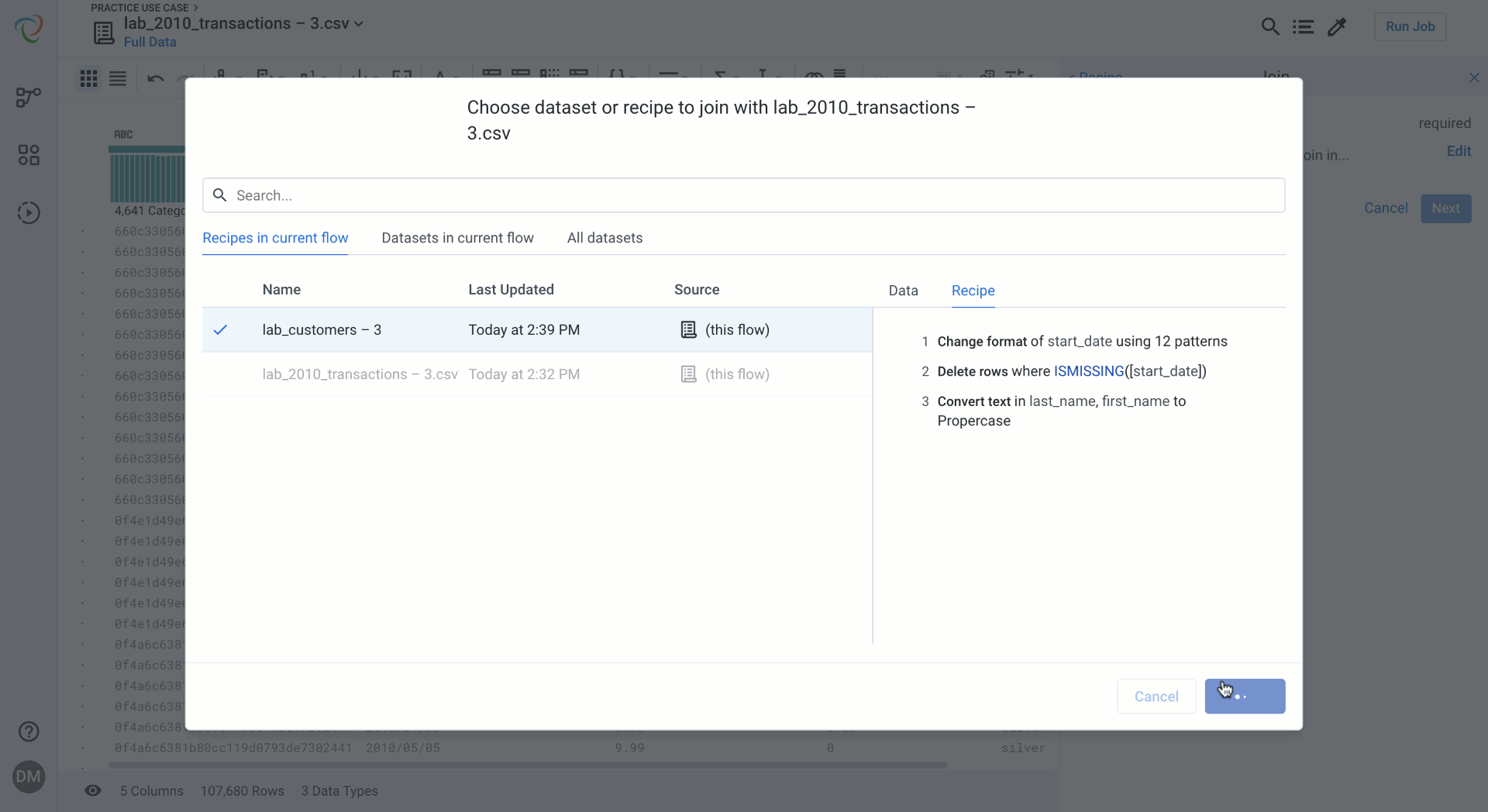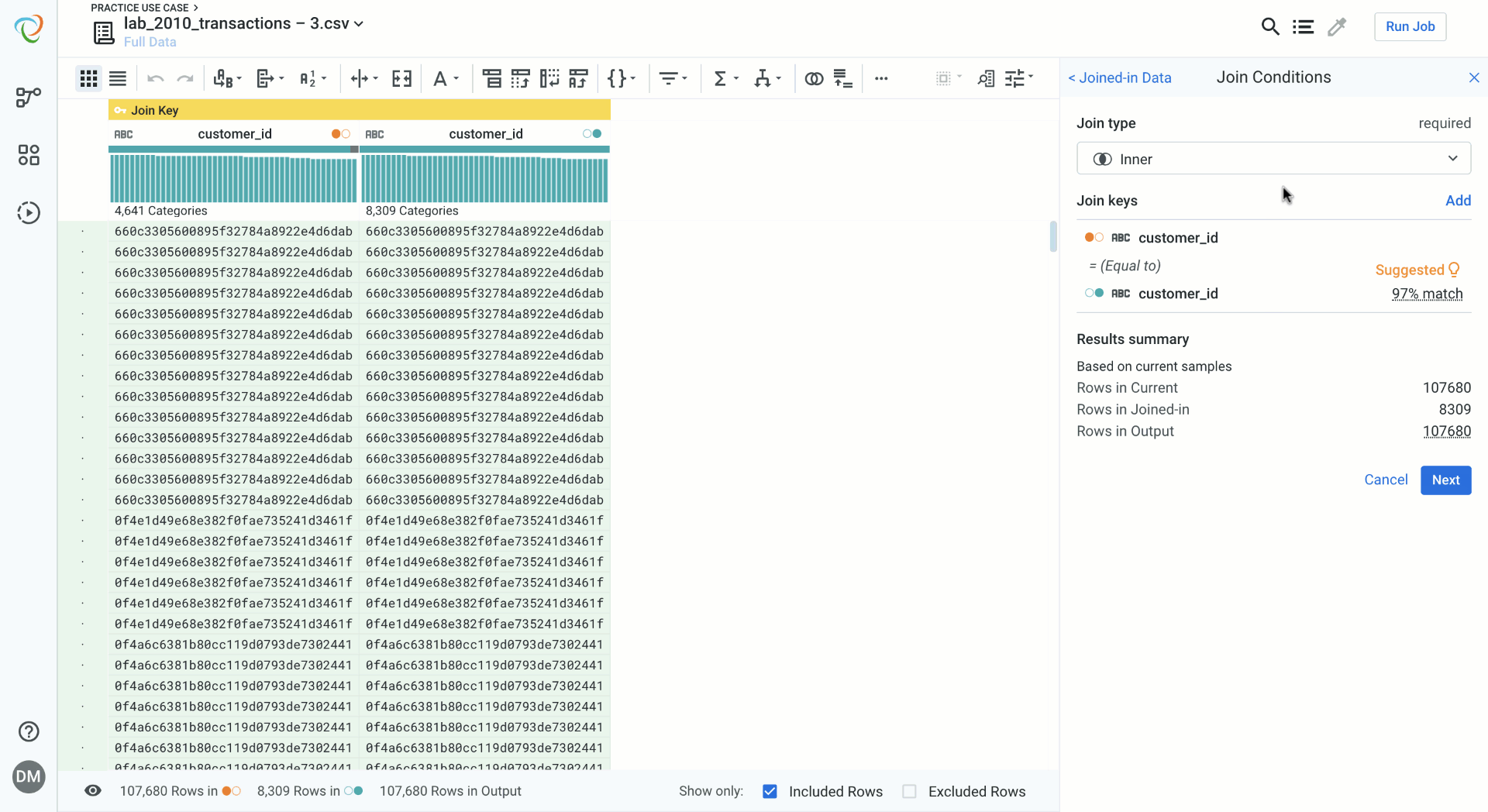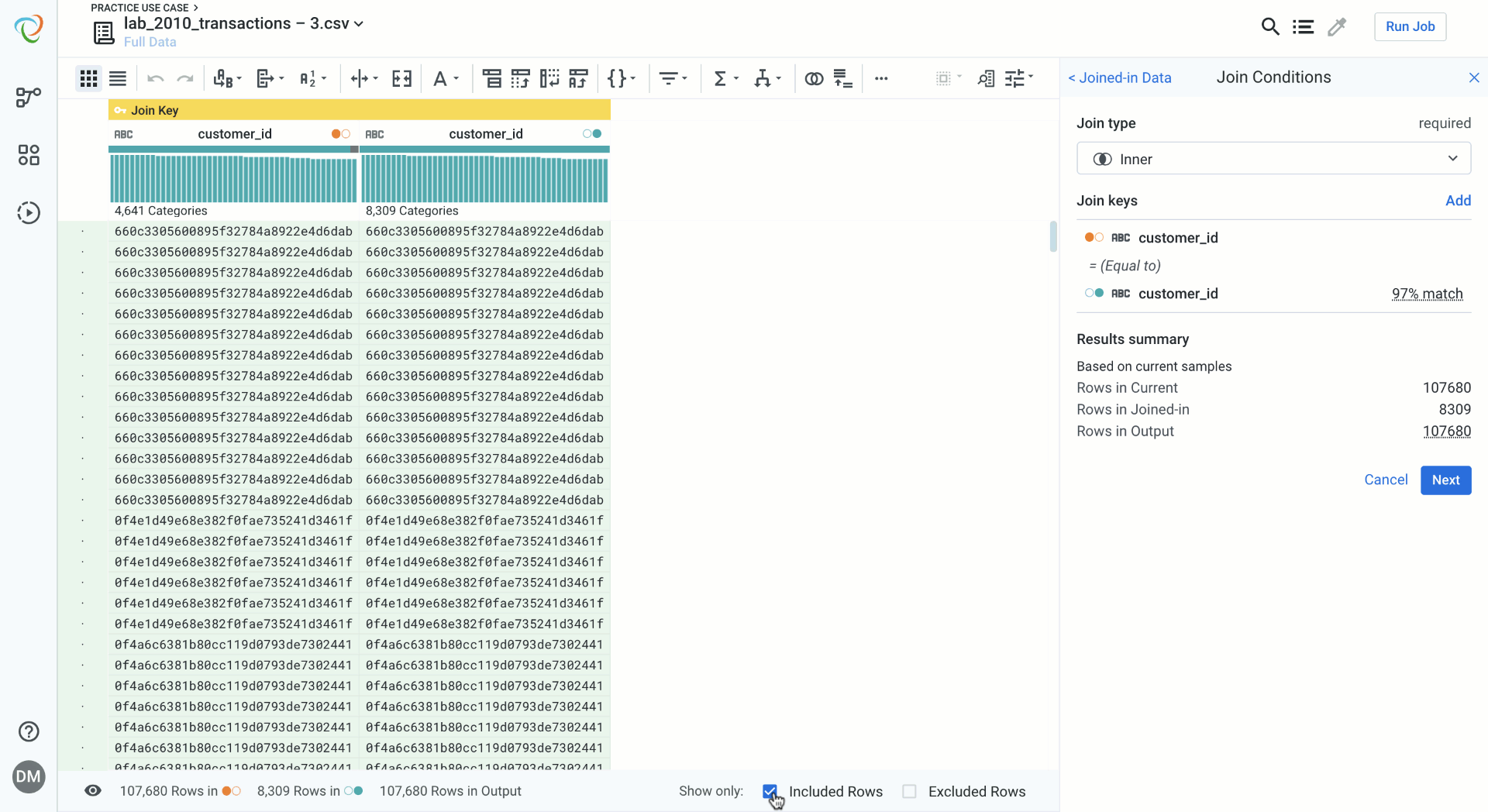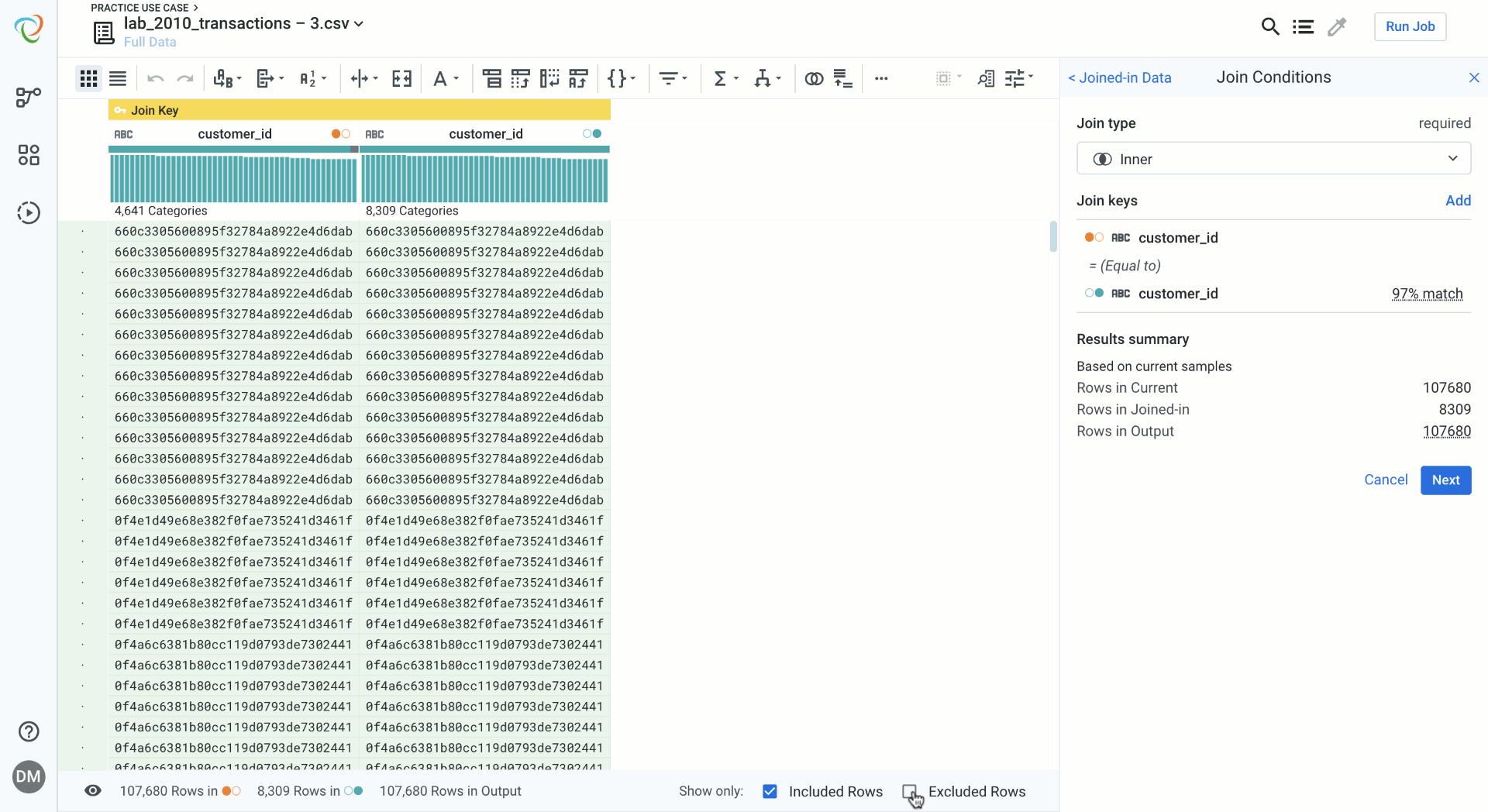
Designer Cloud’s redesigned join interface now lives in the same transform builder as all of the other transformations you are familiar with in Designer Cloud. This provides a familiar data blending experience and doesn’t take you through separate pages. Loading times are significantly improved and previewing the data feels natural. Designer Cloud provides helpful metadata like match percentage of join keys and input/output row count. Join type selection now includes helpful guides to visualize the join type you are selecting. You can also now toggle on and off the rows that will be kept during the join, and those that will be excluded due to no match, which are color coded for guidance.
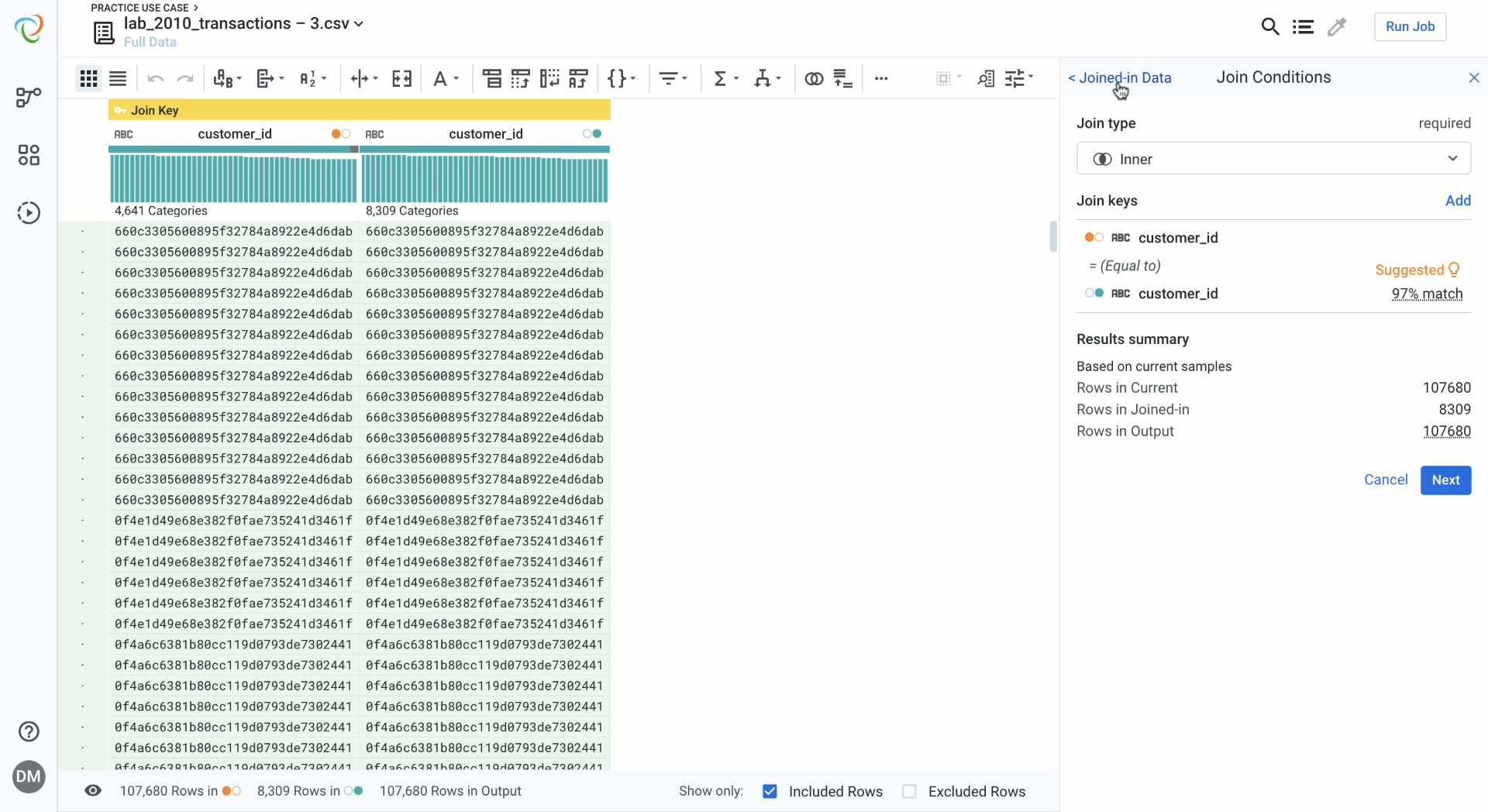
Edit Join Keys
Editing a join key is quick and easy, and again persists the view of your data. You get real time feedback on the effects of changing a join key or selecting other join keys options. These options include fuzzy joins–which match values that are similar but not exact–in addition to ignore case, ignore special characters, and ignore whitespace.
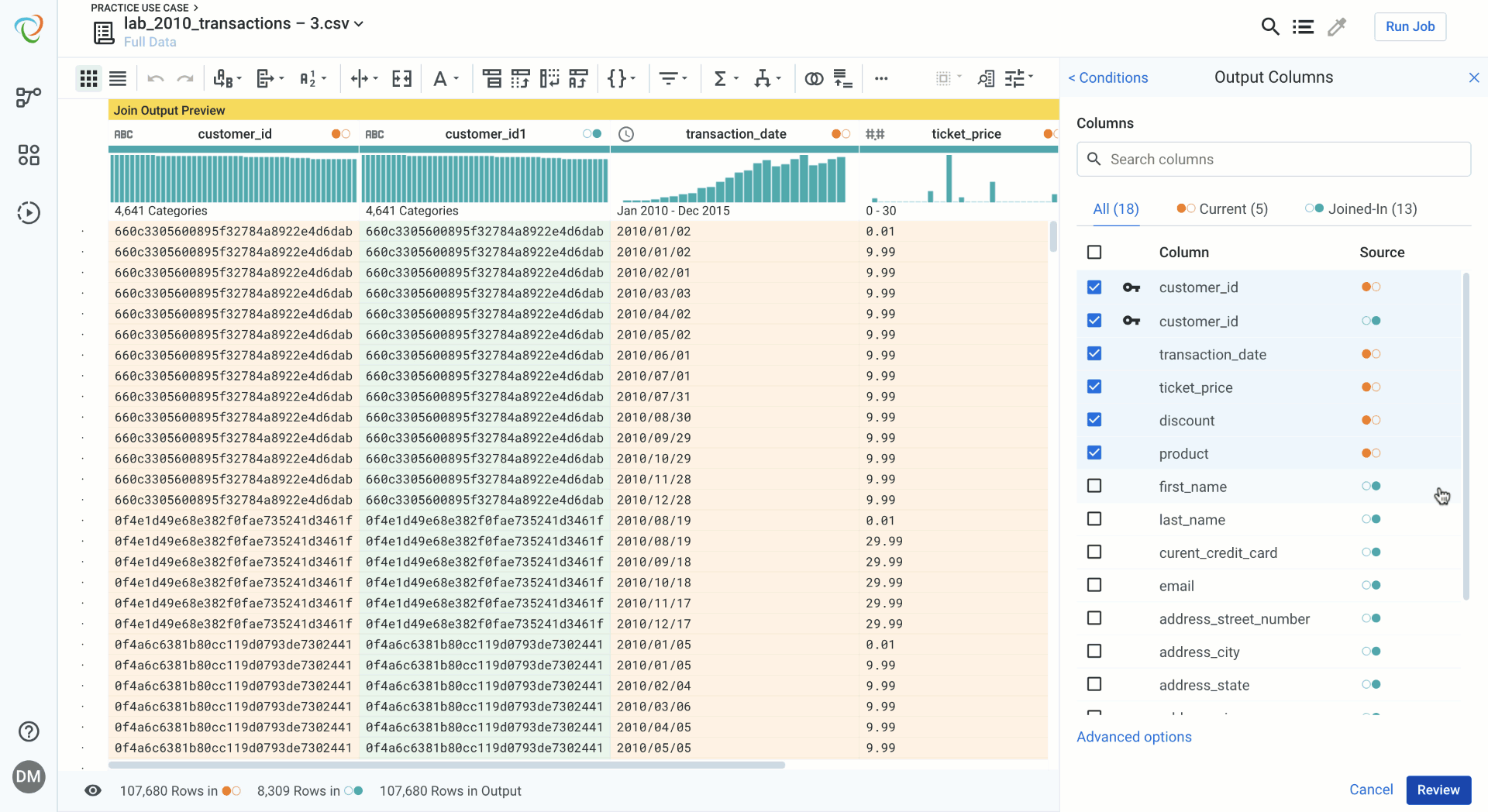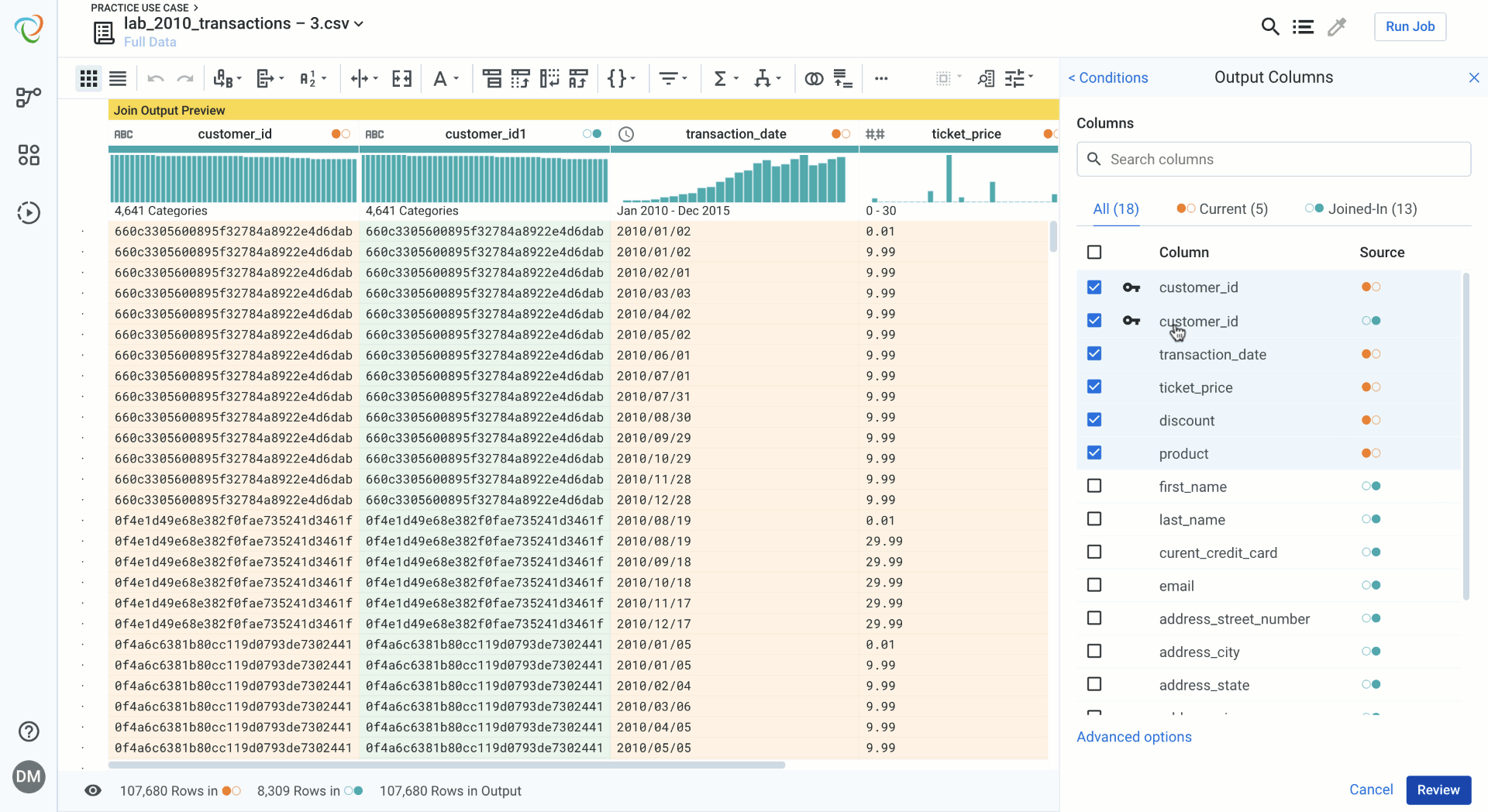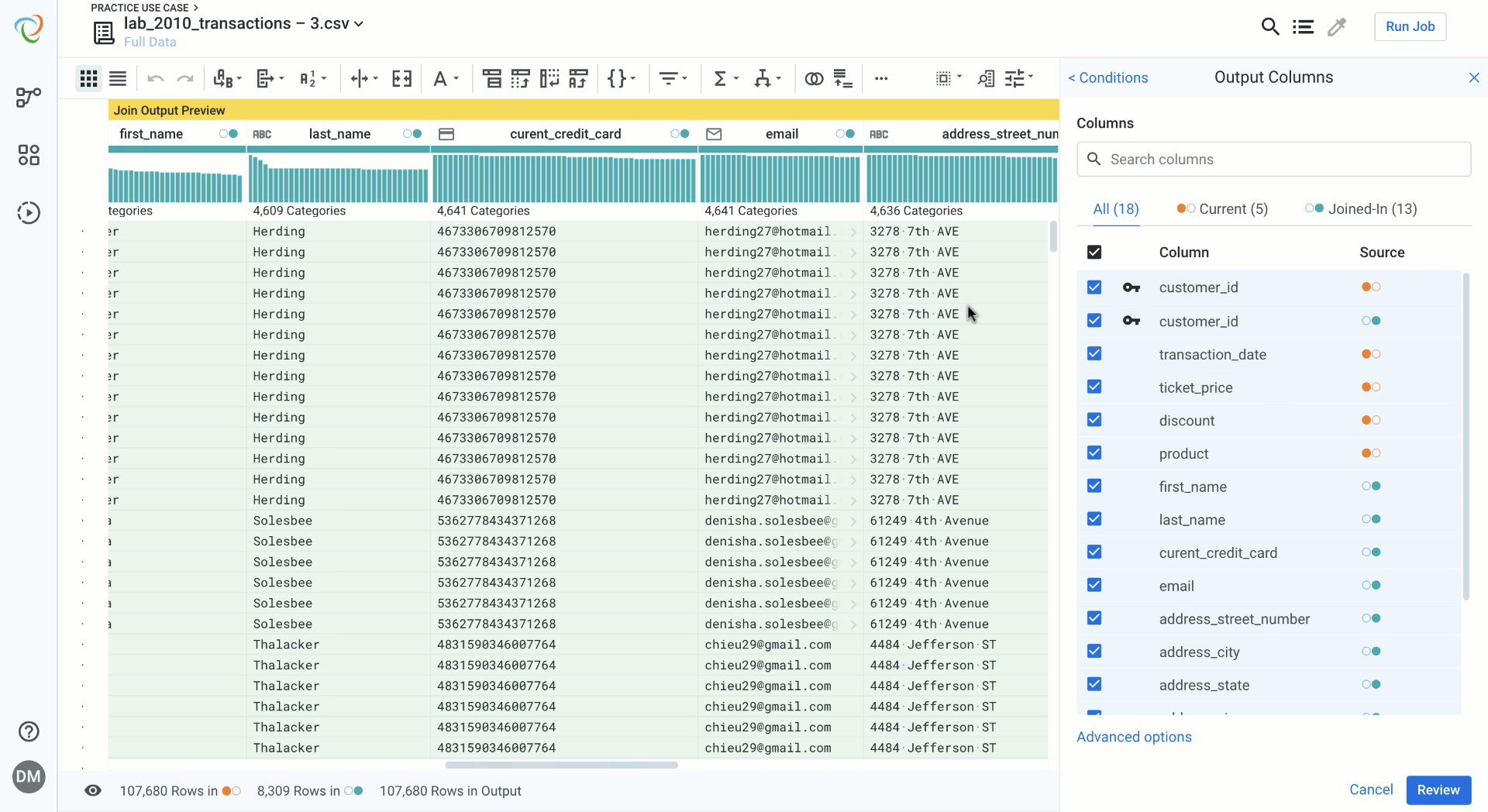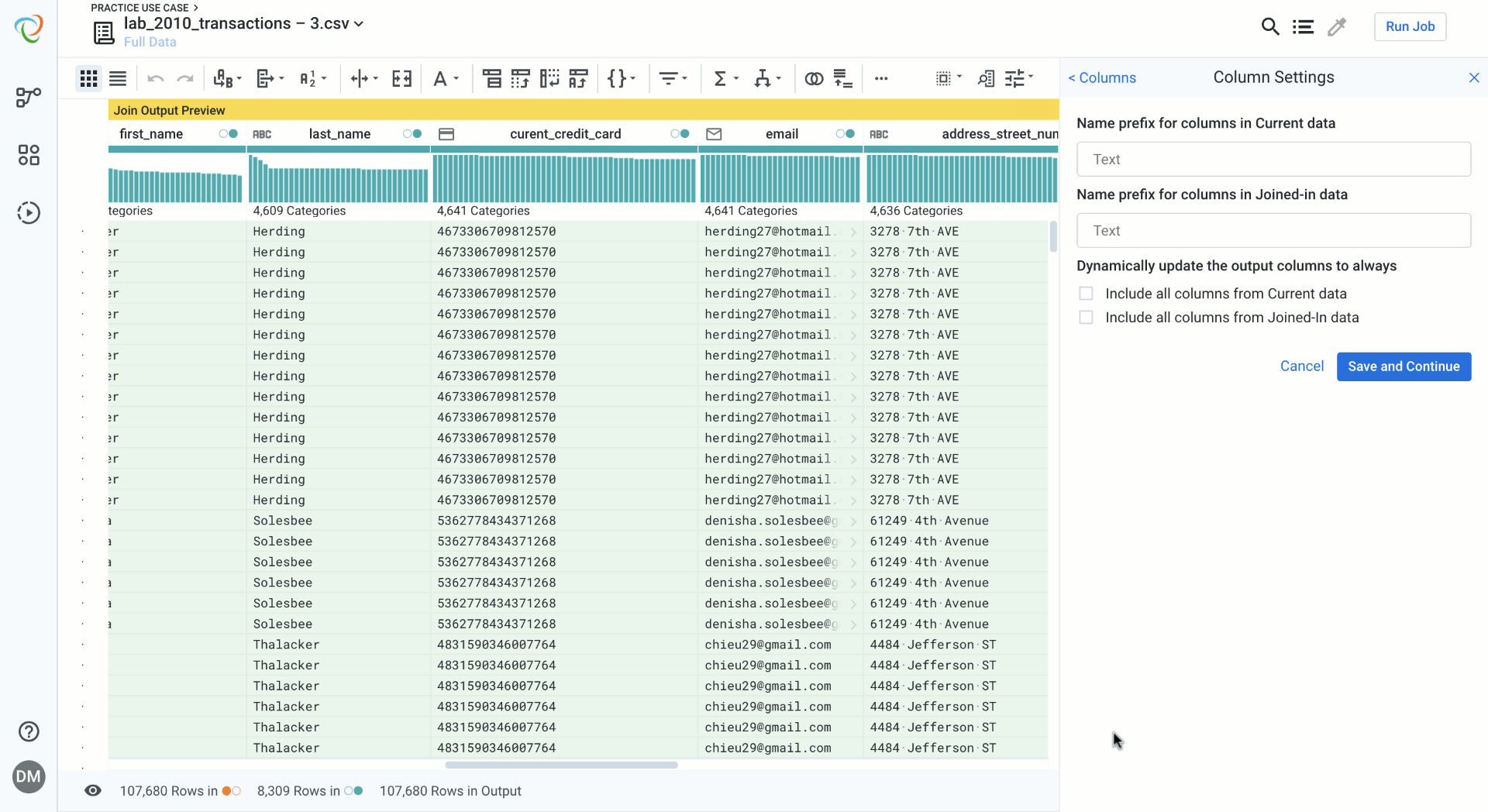
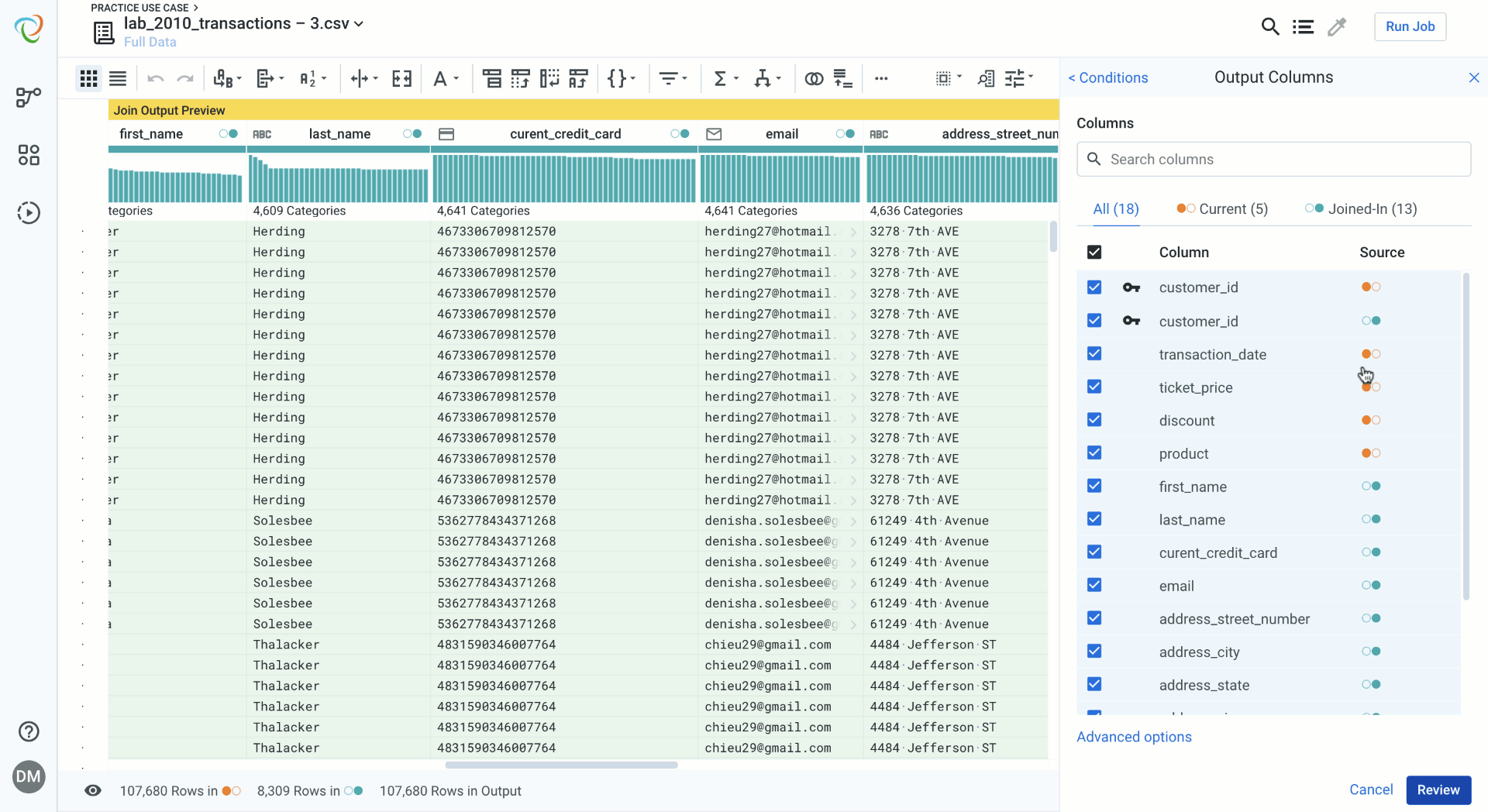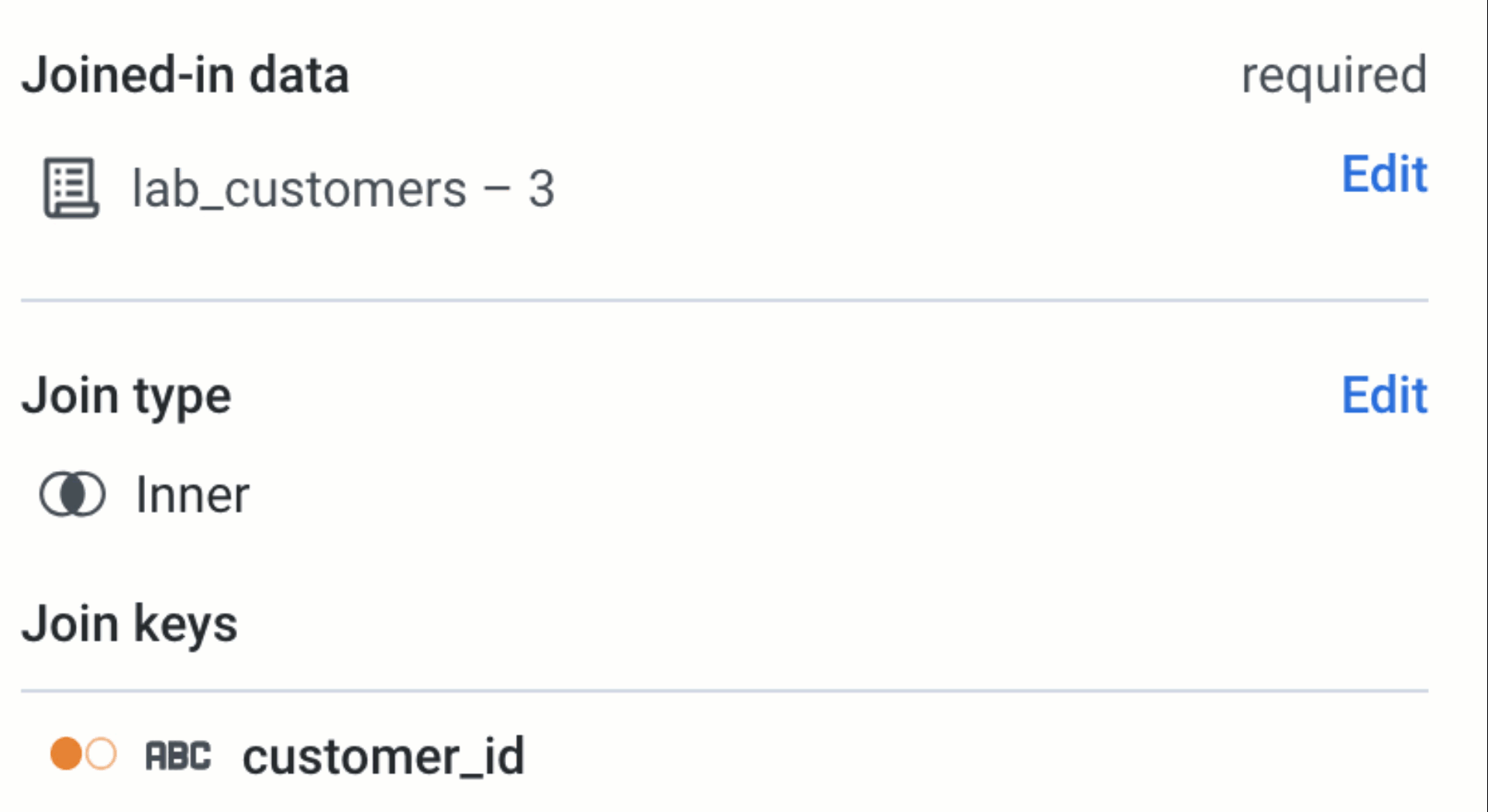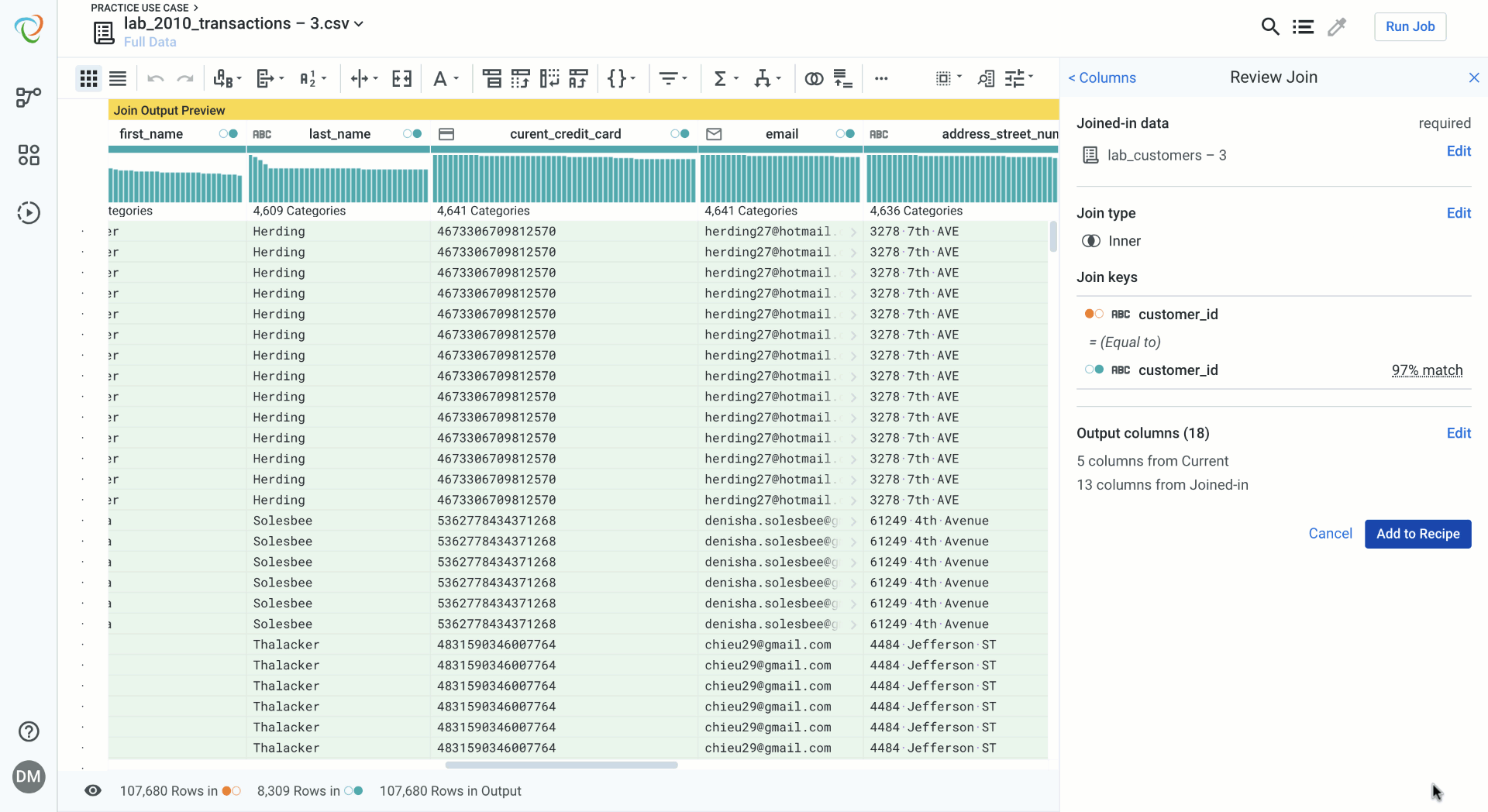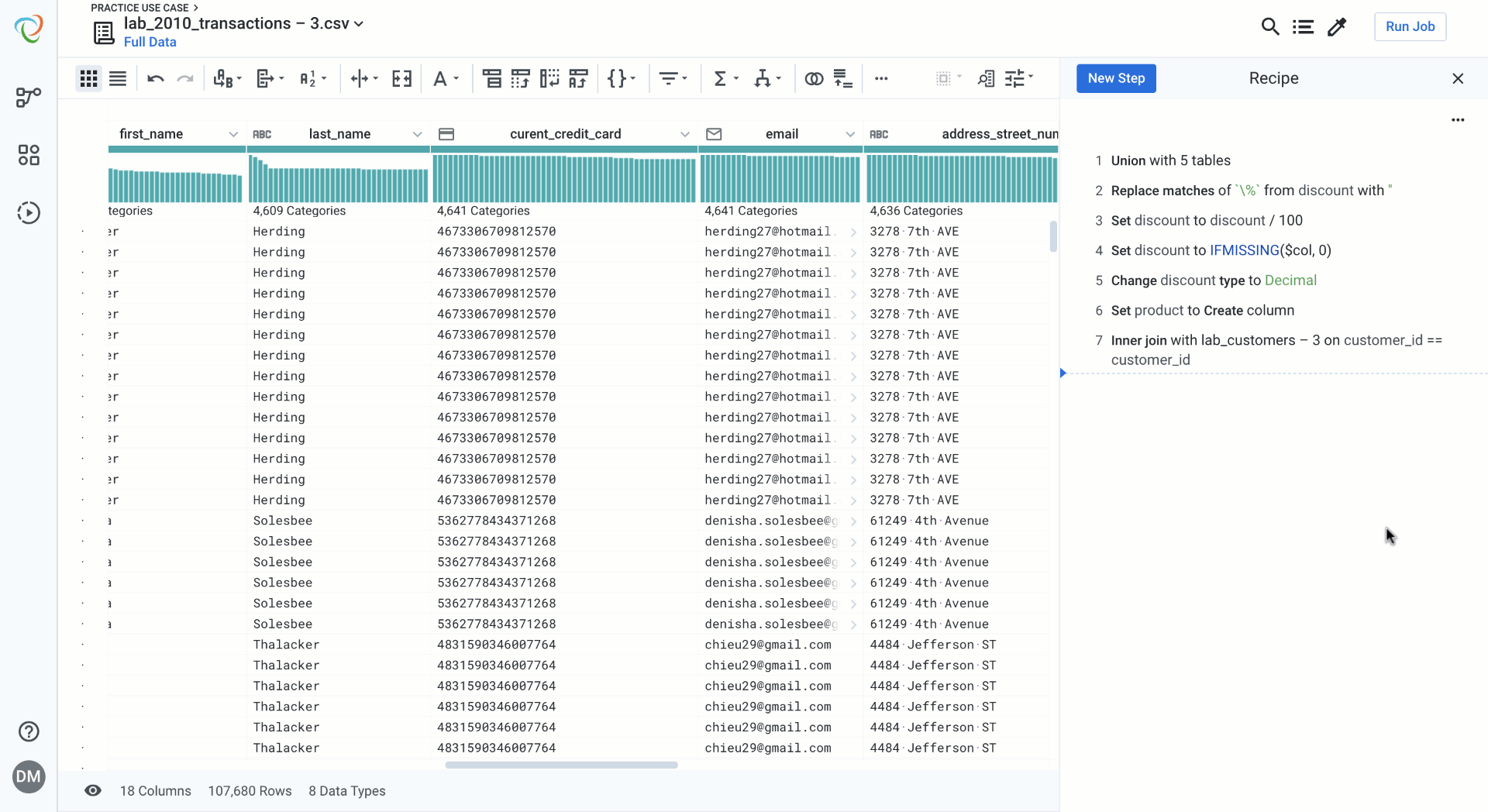
Select and Editing Columns in Data Blending
Columns are now color coded based on the source of the data. You can toggle between datasets for more targeted search and more visibility into the columns that are being included or excluded in the data blending process. Advanced options allow you to add prefixes to columns based on their source, and to toggle on dynamic columns, which will include columns that are added to the source data after the initial join is created.
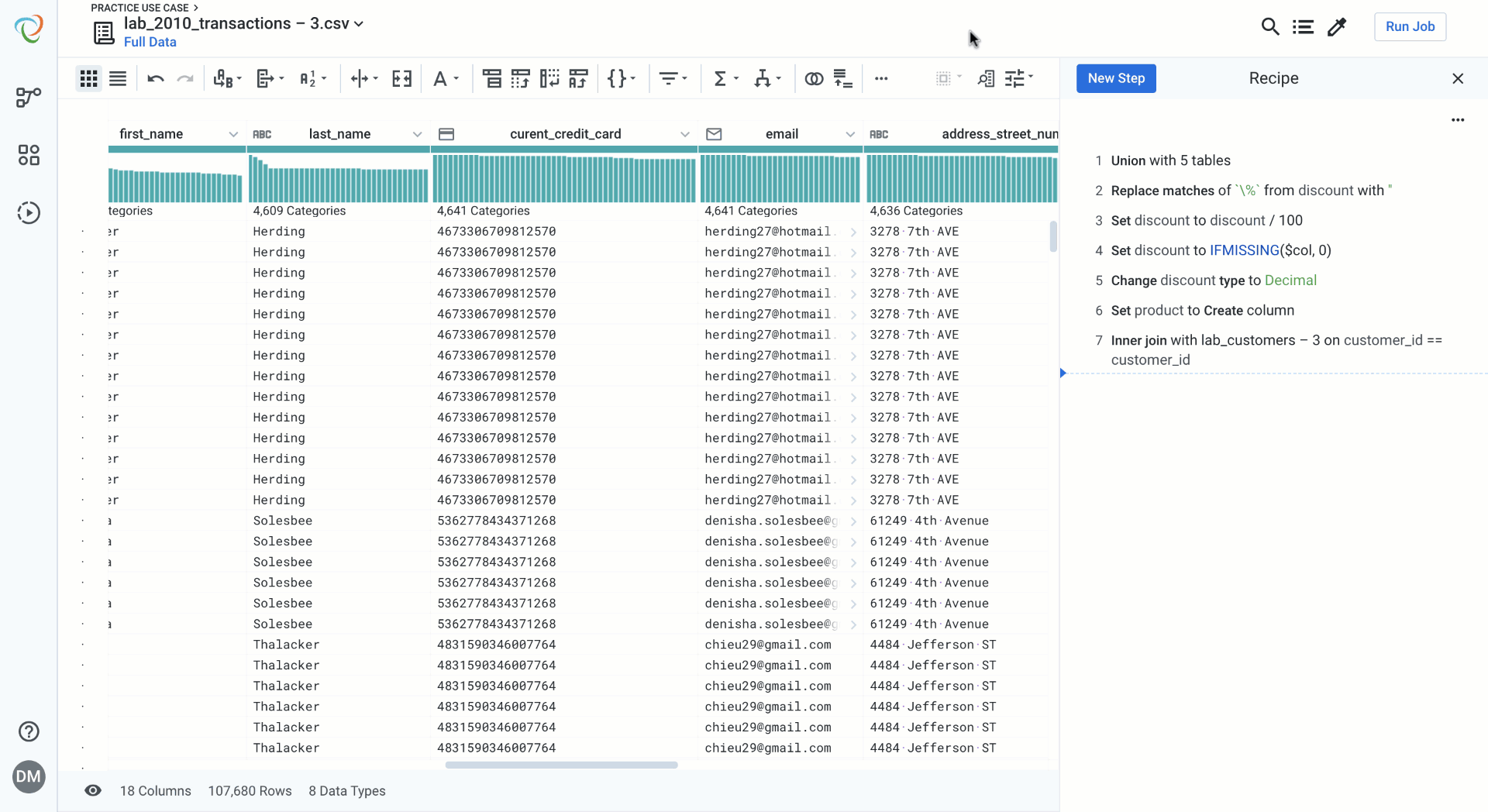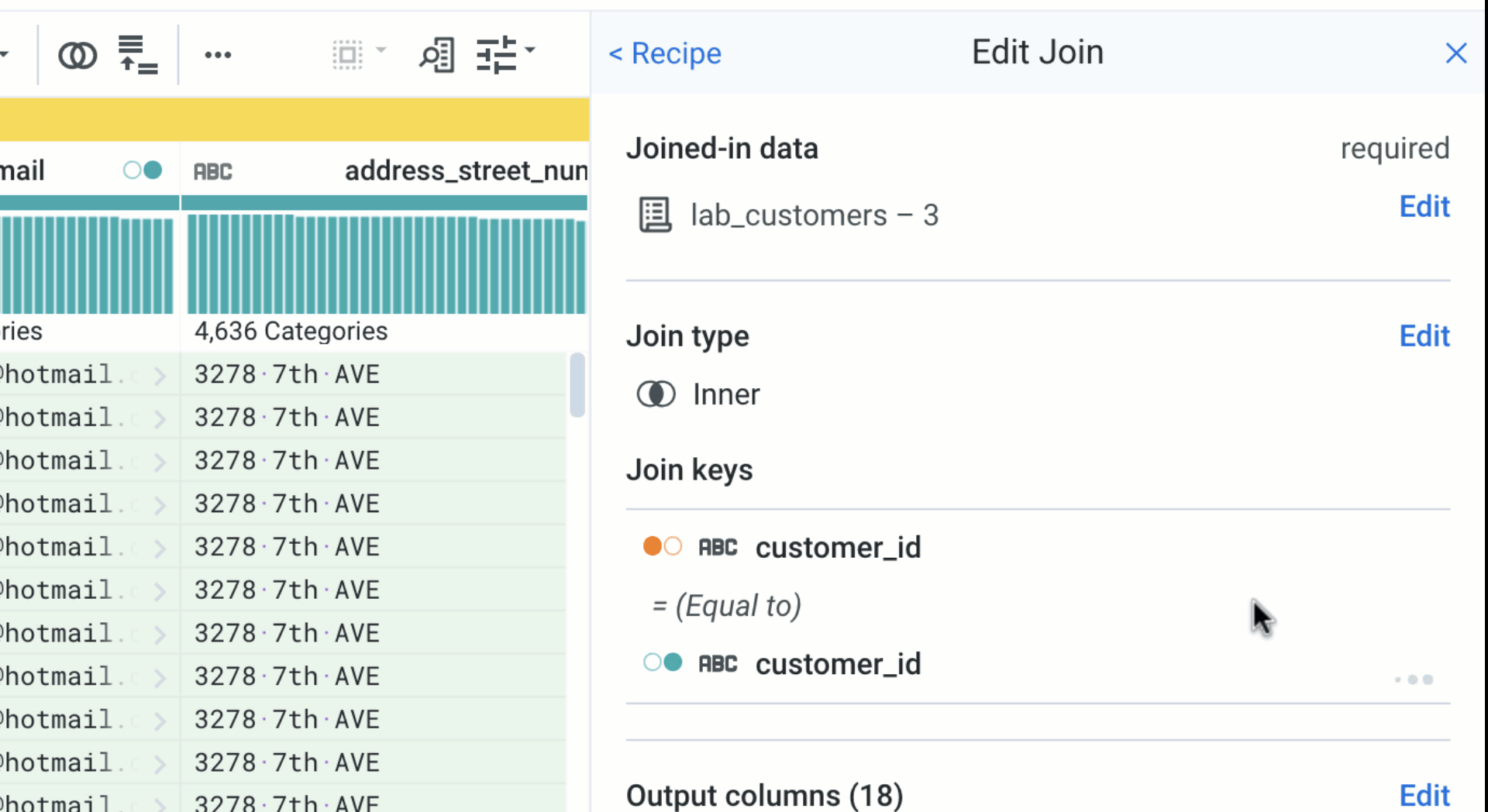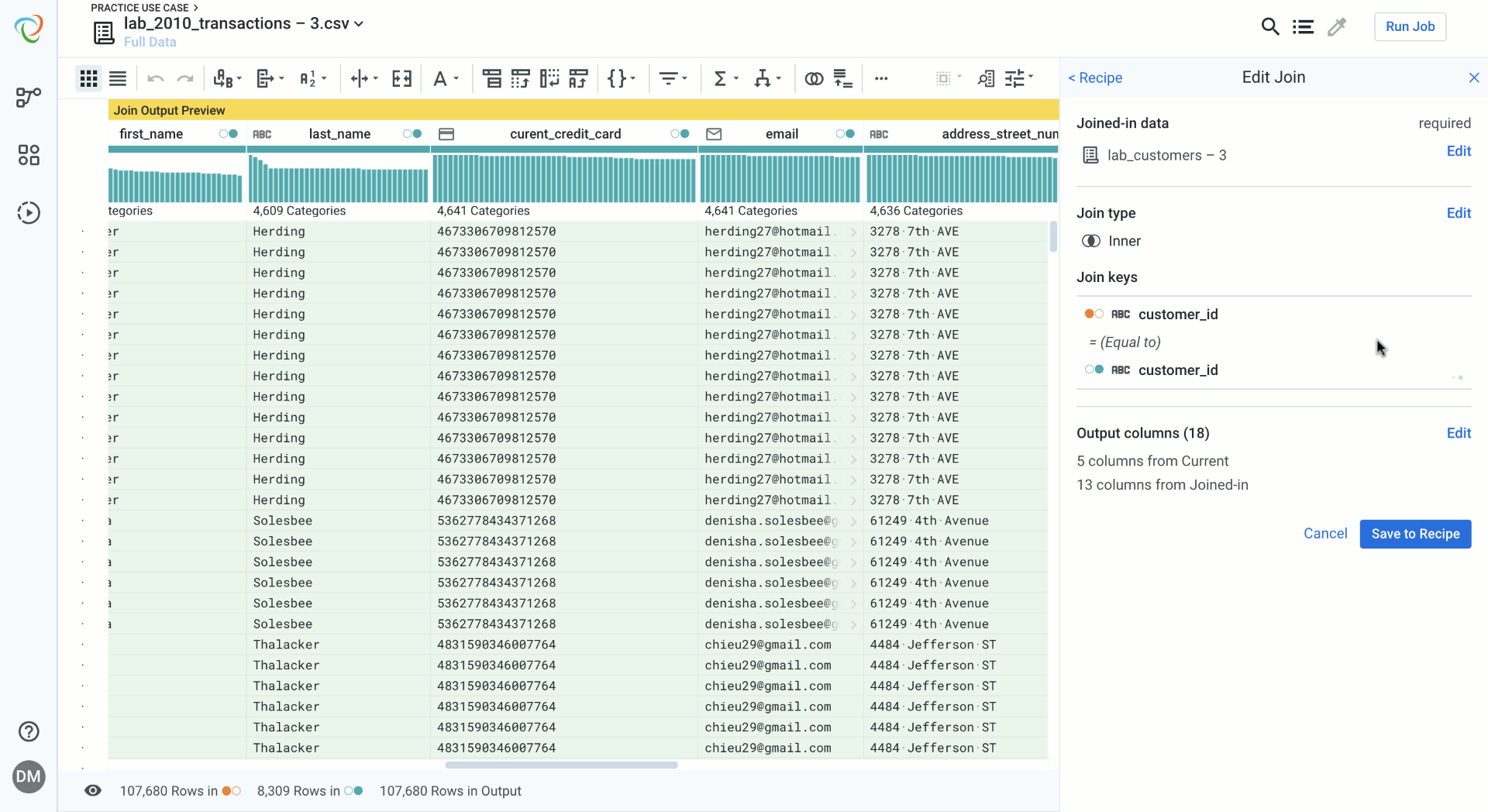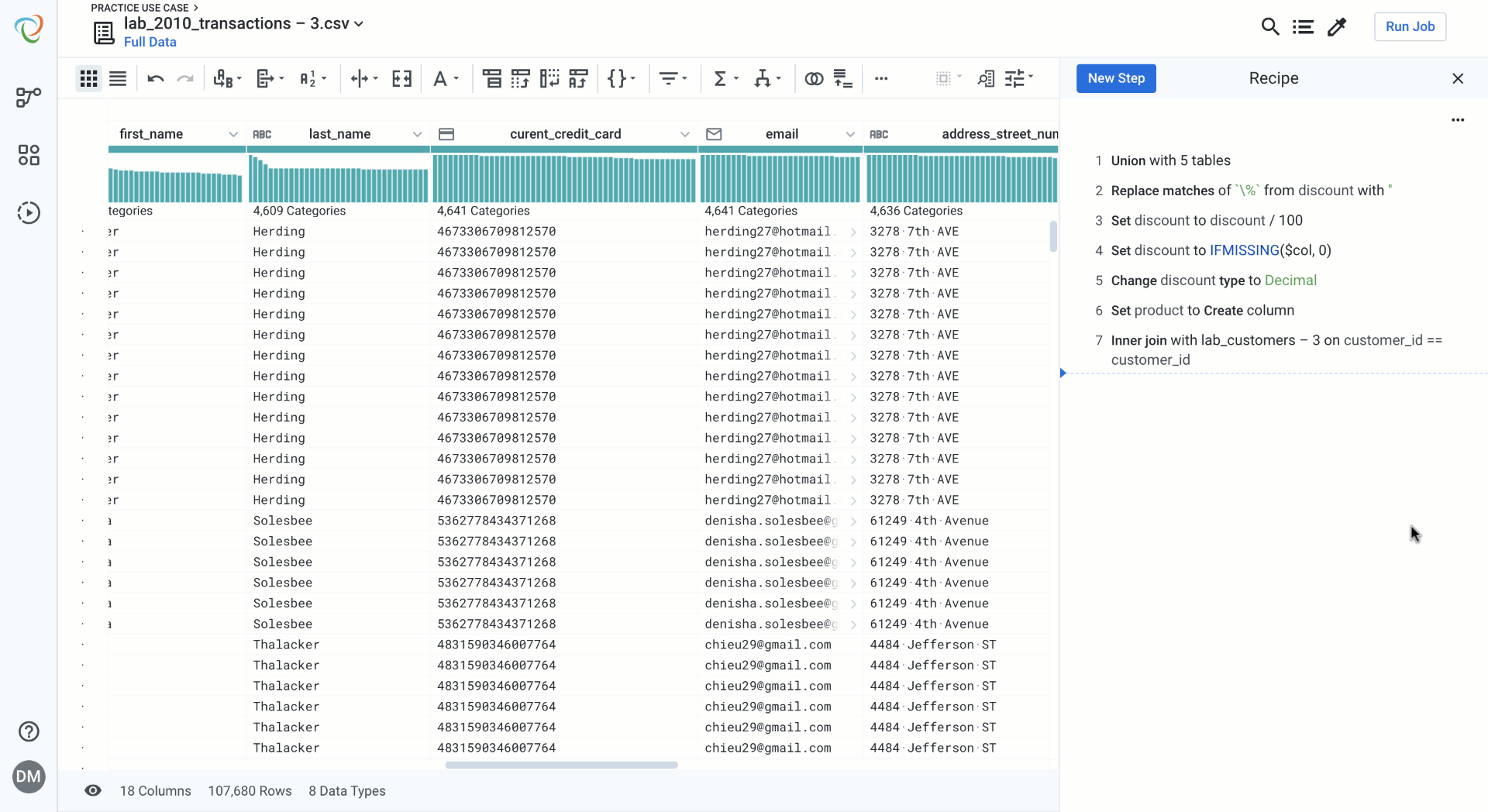
Reviewing your Join while Data Blending
Reviewing your join is a way of checking your work and validating the data blending and the join you have created. If you have made mistakes, editing an aspect of the join is quick and seamless.
Editing Joins
Editing a Join after you have added it to your data blending recipe is now quick and fluid. Selecting edit opens the builder panel with a menu of all the join steps, making it quick and easy to navigate to the join criteria you want to change without having to click through several screens.
Try this feature and many others for yourself by signing up for Designer Cloud trial!