Chefs can do magical things with food. They can take a slate of ingredients and weave them together to create dishes that will hit every single taste bud that you have. They can put a smile on your face, set your mouth on fire with incredible spices, or hit that sweet tooth that you yearn to satisfy.
In the end, though, chefs are only as good as the ingredients they work with.
The same is true for your analytics and predictive models; you may be an analytics chef, but your analytics are only as good as the data you leverage. Unfortunately, one rotten tomato can badly screw up your insight outcomes and lead to bad decisions or predictions, ultimately affecting your business and organizations. Many analysts use data quality checks and tools to find potential pitfalls in the analysis process. With the latest release of Designer Cloud, we are introducing Data Quality Rules, which prevent dirty data from contaminating your data preparation recipes.
What is data quality?
Data Quality Rules allow the user to determine whether the current data is fit for use and, if not, what additional transformations are needed. Data Quality Rules assess – thanks to predictive suggestions – the data set and provide a list of indicators to monitor and track the data’s cleanliness in your systems over time.
Why is the Data Quality Rules feature important?
As you know by now, the quality of an analytical or ML/AI predictive outcome is only as good as the data that feeds its logic. Data Quality Rules provide an automated way to identify data flaws and build quality indicators to monitor its remediation. The state of your Data Quality Rules is automatically updated to reflect changes, and they can be used to prevent any undesired transformation over time. If you delete columns or other elements referenced in the Data Quality Rules, errors are generated in the Transformer page.
Ultimately, the rules can monitor the accuracy, completeness, consistency, validity, and uniqueness of the data you leverage in your analytics initiative and ensure you have a comprehensive view of the cleanliness of the data. Consider integrating the feature into a data management strategy.
How does the Data Quality Rules feature work?
A new icon has been added to the transformation grid:

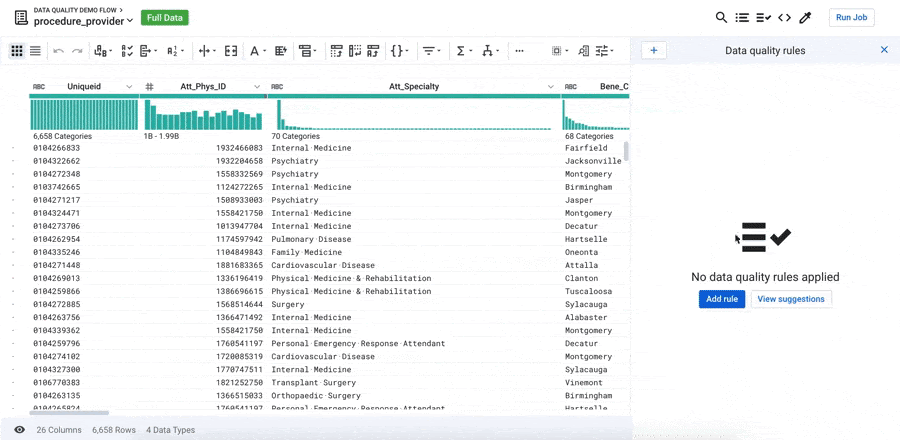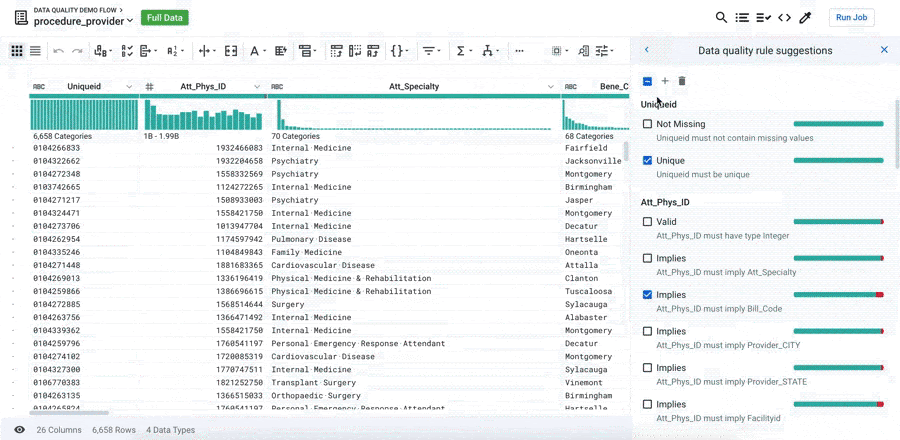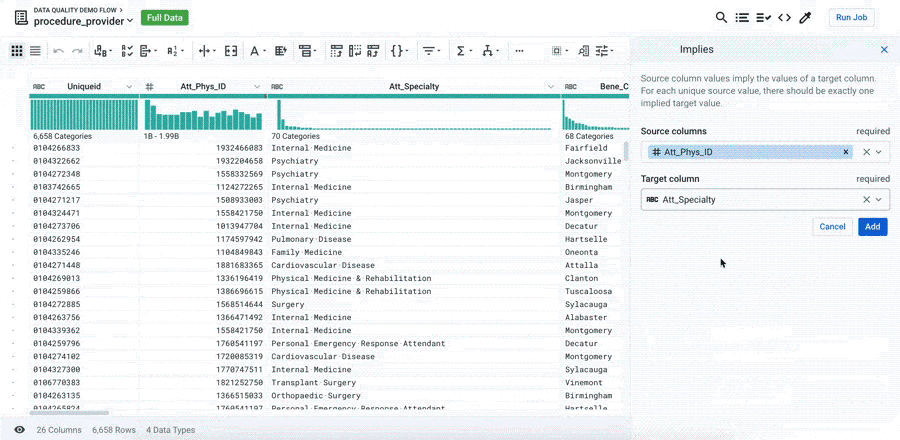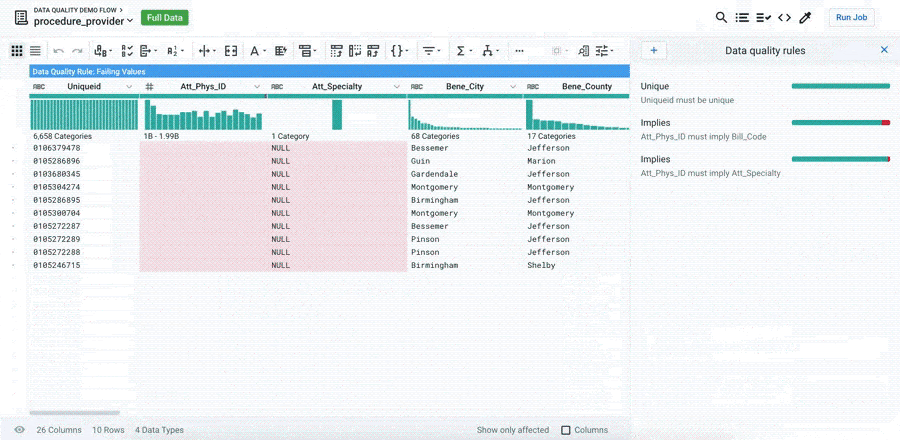
When you click the “View suggestion” button, Trifacta automatically suggests a series of Data Quality Rules to validate various aspects of the data’s quality. For example, is the value unique or empty, does it fit a pattern, is it in an expected range, or does it correlate to another column?

From there, you can accept, remove, edit, or add to the Data Quality Rules to ensure they are fit for your particular use-case for this data.

You can add your own rules by leveraging the power of the Designer Cloud language to build any validation rule you may have in mind.
 What else?
What else?
Data Quality Rules are another step forward in our Adaptive Data Quality strategy, which adapts in accordance with your specific and personalized requirements. You can learn more information about Designer Cloud’s Data Quality Vision, and particularly Adaptive Data Quality, by reading the blog from Jeff Heer, Trifacta’s Co-Founder and Chief Experience Officer.
Haven’t had a chance to try Designer Cloud yet? START FREE today!