Recently, we announced new functionality to support data engineers within growing data operations (DataOps) practices. This is an exciting shift as we see the role of data engineers growing increasingly important and critical to helping our platform expand and mature. Data engineers are leading the charge to scale data preparation across the organization and ensure that data prep workflows are efficient, repeatable, and governed. As the role of data engineers expands, we’re continuing to update the Designer Cloud platform to ensure it meets their needs. Our latest functionality demonstrates Alteryx’s commitment not only to the end user, but also to the critical collaboration between those end users and data engineers.
In an earlier blog, my colleague Sean discussed how RapidTarget is allowing data engineers to set a predefined schema target. Now we’re excited to talk a little more about Automator, our system to intelligently manage scaling, scheduling and monitoring data prep workflows in production.
Introducing Automator
Often, there’s little control over how the data that needs to be wrangled is organized. Instead, data engineers must work with what they have. We’ve introduced parameters and variables to help data engineers deal with these situations. They allow data engineers to specify what input data they want Designer Cloud to use each time a job is run. Parameters and variables can be used in datasets created off of both files and databases.
Working With File Paths
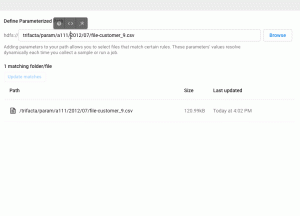
When data engineers read files from a file system they need to work around how the data is organized. They might have dates split across multiple levels of their path or file name, parts of a path data engineers may want to match to any instance of a pattern (like an email address), or parts they want to be able to set a value for later on when they set up a schedule, kick off a job, or invoke Designer Cloud’s APIs (like a geographic region, customer name, etc…). In order to do all this (and more) data engineers can now use three new features when defining their file paths: datetime parameters, pattern parameters, and variables. I provide an overview of each in the following section.
Datetime parameters let data engineers point out dates or times in their file paths and define rolling ranges that Designer Cloud will dynamically resolve at job run time. This lets them do valuable things like match the last two weeks of files partitioned by date (e.g. 2018/04/orders_25.csv).

Pattern parameters let data engineers use wildcards or regular expressions in their file paths. They can do things like use a wildcard to ignore the file extension or use a regular expression to select all folders that match an email address.

Variables let data engineers define a part of a path that they’ll have the ability to override later on when running a job, setting up a schedule, or invoking Designer Cloud’s APIs.

Data Engineers can use all three together to create powerful file matching rules.
Variables in Custom SQL
Designer Cloud’s custom SQL editor already provides a powerful way for those data engineers that are comfortable writing SQL to select exactly the right data. They can select columns, filter their data, pre aggregate, create calculated fields, and join with other tables in their database all before bringing their data into Designer Cloud to wrangle. We’re making it even better by letting them use variables in their r SQL statements. Data Engineers can replace as much or as little of their SQL statement as they want with a variable.

Like with file paths, data engineers have an opportunity to pass values in for their variables when they run a job, either from within the application or via our API.

What’s Next
We’re excited about the release of Automator, which gives data engineers critical control over scaling, scheduling, and monitoring data prep workflows. Stay tuned for our final blog in the series where we’ll review the final feature in this release, Deployment Manager.